Summary
We proposed a joint extraction model that can handle overlapping and nested problems. It is a single-stage model without any gap between training and inference, which means it is immune to exposure bias.
Background
Relation extraction is a technique to extract entities and relations from unstructured texts. It plays an essential role in many natrual language understanding tasks, such as text understanding, question answering (QA), and information retrieval (IR). In short, it is a typical task to extract knowledge of relations in the form of (subject, predicate, object).
For example: 1
2
3
4
5
6
7
8
9
10{
'text': 'Gone with the Wind is a novel by American writer Margaret Mitchell',
'relation_list': [
{
'subject': 'Gone with the Wind',
'object': 'Margaret Mitchell',
'predicate': 'author'
},
]
}
Early works address this task in a pipelined manner. They first identify all candidate entities and then classify the relations between each two entities. These methods ignore the interaction between named entity recognition and relation classification and suffer from error propagation.
In order to utilize the information between two tasks, researchers proposed many models to extract entities and relations jointly. Joint learning helped improve the performance, while some early joint models, like NovelTagging, can not handle relation overlapping problems (see the table below). When entities occur in multiple relations, naive sequence labeling can not work well and usually miss some relations.
| Text | Triplets | |
|---|---|---|
| Single Entity Overlapping | Two of them, Jeff Francoeur and Brian McCann, are from Atlanta. | (Jeff Francoeur, live in, Atlanta)(Brian McCann, live in, Atlanta) |
| Entity Pair Overlapping | Sacramento is the capital city of the U.S. state of California. | (California, contains, Sacramento)(California, capital, Sacramento) |
Some models have been proposed to tackle these problems,such as CopyRE, CopyMTL, CasRel(HBT), but they have the problem of exposure bias. They use ground truth as input to guide the median training process but in inference stage they use predicted results instead, leading to a gap between training and inference.
For the decoder-based method (Figure 1), at training time, the ground truth tokens are used as context while at inference the entire sequence is generated by the resulting model on its own, and hence the previous tokens generated by the model are fed as context. As a result, the predicted tokens at training and inference are drawn from different distributions, namely, from the data distribution as opposed to the model distribution.

These models can jointly extract entities and relations by a single model, while in a way they regressed to pipelined methods since they do decoding by multiple interdependent steps. And this is the essense of why they have the exposure bias problem.
The rest sections will introduce a model that can wipe out exposure bias and guarantee the consistency of training and inference.
The tagging schema

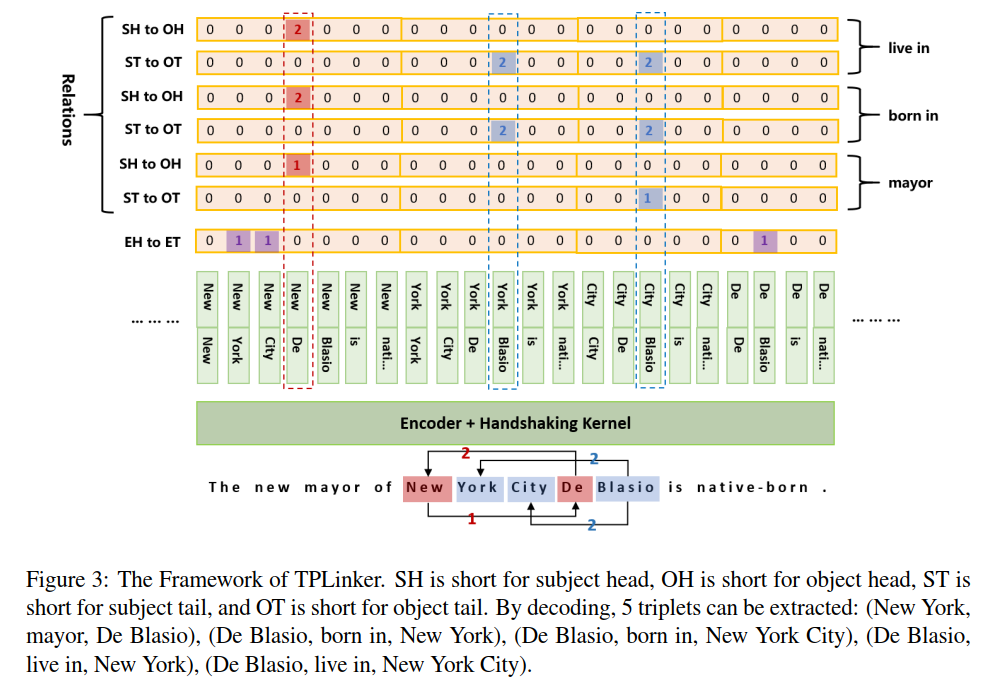
In a matrix, we tag the link between each two tokens in a sentence. The purple tag refers to that the two correspond-ding positions are the start and end token of an entity. The red tag means that two positions are the start tokens of paired subject and object entities. The blue tag means two positions are respectively the end tokens of paired subject and obj-ect entities.

Because the entity tail is impossible to appear before the head, to save resources, we map relation tags (red and blue) in the lower triangular region to the upper one and drop the whole lower region.
Model
Token Pair Representation
Given a sentence, we first map each token into a low-dimensional contextual vector by a basic encoder. Then we generate a representation for the token pair by Equation 1: \[h_{i,j} = tanh(W_h \cdot [h_i; h_j] + b_h), j \geq i \tag{1}\]
Handshaking Tagger
Given a token pair representation by Equation 2, the link label of a token pair is predicted by Equation 3: \[ P(y_{i,j}) = Softmax(W_o \cdot h_{i,j} + b_o) \tag{2}\] \[ link(w_i, w_j) = argmax_l P(y_{i,j} = l) \tag{3}\]
Decoding
In the case of Figure 5, (“New”, “York”), (“New”, “City”) and (“De”, “Blasio”) are tagged as 1 in the EH-to-ET sequence, which means “New York”, “New York City”, and “De Blasio” are three entities. For relation “mayor”, (“New”, “De”) is tagged as 1 in the SH-to-OH sequence, which means the mayor of the subject starting with “New” is the object starting with “De”. (“City”, “Blasio”) is tagged as 1 in the ST-to-OT sequence, which means that the subject and object are the entities ending with “City” and “Blasio”, respectively. Based on the information represented by these three sequences, a triplet can be decoded: (“New York City”, mayor, “De Blasio”).
The same logic goes for other relations, but note that the tag 2 has an opposite meaning to the tag 1, which represents a reversal link between tokens. For example, (“York”, “Blasio”) is tagged as 2 in the ST-to-OT sequence of relation “born in”, which means “York” and “Blasio” are respectively the tail of a paired object and subject. Associated with the other two sequences, the decoded triplet should be (“De Blasio”, born in, “New York”).
Experimental results


Future work
Some points to further improve the performance:
We use concatenated vectors to represent the relation between two tokens, which may not be the a good way to approach the best performance.
We use the same representation to classify entities and relations. This may lead to interference between two tasks instead of mutually improvement. Two recent works demonstrated that using different representation might achieve a better performance: A Frustratingly Easy Approach, Two are Better than One
The model extend the original sequence from \(O(N)\) to \(O(N^2)\), which adds the cost significantly and make it an expensive task to deal with long sequences.
More Info
If you want to know more details of this work, please see our paper or source code. Please do not hesitate to email me or open an issue if you have any questions about the code and the paper.